
qPCR检测中极低浓度样本取样和随机误差对结果的影响分析
背景介绍
无论在化学检验还是医学检验中,极低浓度样本检测均极为困难,检测精度的进步是随着人类对少量、微量、痕量物质检测的要求而一步步提升起来的。回到医学检测领域,被测物质的低值检测能力一直是衡量产品质量的一个最关键的指标,但在信号放大和检测方法没有革命性改变的情况下,极低浓度样本的测定是否存在一个偏差上限呢?如果仅仅考虑取样随机误差,结果会受多大的影响?本文将试图通过建设一个取样模型进行分析,欢迎业内专家们批评指正,抛砖引玉欢迎大家提出更多更符合实际情况的取样模型。
实验过程
假设现采用qPCR检测试剂盒对已明确定值为50IU/ml乙型肝炎病毒血清样本进行定量测定,取血清样200μl,核酸提取富集为50μl,其中20μl用做模板上机进行测定,最终根据标准曲线计算出浓度值;
20个重复记为一组,对浓度值取对数后计算均值、CV;
注意,因实验模型设置仅考虑取样误差,固认为实验过程完美,不考虑以下可能性误差:
-
操作过程
-
样本浓度偏差
-
DNA在样本中均匀分布,不考虑泊松分布情况
-
各品牌对病毒核酸IU单位和拷贝单位的换算关系差异
-
IU与拷贝换算关系定为1:1
-
试剂储存及使用
-
标准品制备
-
核酸提取损耗
-
加样体积准确性
-
核酸扩增效率
-
荧光阈值调整
-
标品定值曲线拟合度
-
其他可能引起结果定值偏差的情况
取样模型
前提:
浓度为50IU/ml的血清准确量取200μl,其中包含的DNA拷贝数量为10;
提取富集后的核酸溶液体积为50μl;
取样体积20μl;
取样模型描述:
假设将提取富集后的核酸溶液分割为1000个箱子(编号为1,2,3,……,1000);
其中编号为100倍数的箱子内包含DNA片段(编号为100,200,300,……,1000);
从1000个箱子中随机抽样400份,记录箱子编号,统计编号为100倍数的箱子数量(即为抽到的DNA数量,期望值为4,对应浓度值为50IU/ml,取对数为1.69897);
随机取样20次,得到20次抽取DNA数量的记录,计算得到一组浓度对数均值和CV;
如取样中未取到DNA,则对剩余的有效记录计算均值和CV;
数据结果及分析:
计算获得1万组数据,将浓度对数均值和CV从大到小按照等距分为100组,用柱形图对浓度对数均值和CV频次进行分析。
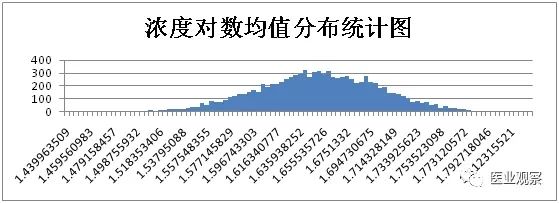
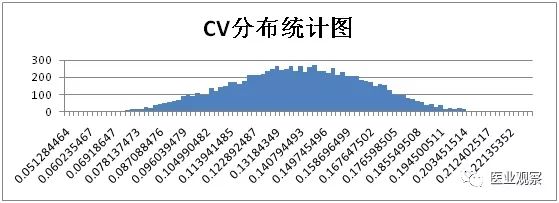
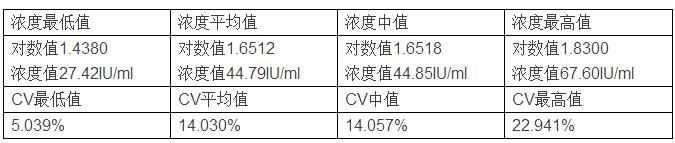
综上,仅考虑取样时的随机误差时,浓度50IU/ml样本实验结果统计如下:
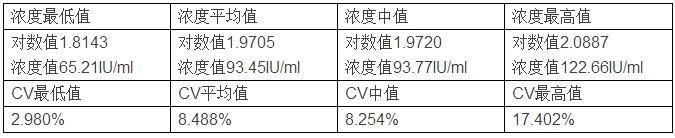
同等条件下,如果样本更换为100IU/ml,随机抽样结果如下:
结论:
随着方法学的不断成熟,很多以前不能检测的微量甚至痕量样本都可以进行测定,但每种方法学都有自己的检测阈值下限,理论上是不可能突破方法学和实际操作流程限制来人为拔高检测精度的。
随机抽样和笔者实际实验表明用qPCR方法对极低值样本(≤100IU/ml)进行检测定值是个极为困难的事情,实验CV能控制在5%以内几乎不可能。不知道其他实验室或研发人员是否有精度控制的独门绝招可以大幅降低实验偏差。
我们希望能看到更多更好的产品出现,客观公正得对产品进行性能评估,也希望有更划时代的方法学出现,让我们的医学检测更加精准,为患者的早筛查、早诊断、早治疗做出贡献。
参考资料:
核酸扩增法检测试剂注册技术审查指导原则
YY/T 1182-2010核酸扩增检测用试剂(盒)
关于HBV-DNA及HBsAg定量单位IU/ml、copies/ml和ng/ml之间的换算问题
- 上一篇:常见不同材料包覆磁珠的性能比较 2017/8/10
- 下一篇:分子生物学实验室需要配置的仪器清单 2017/7/31